Ankit B V S
Data Science Intern
University of Illinois at Chicago
Biography
Highly-determined Data Science graduate having 3+ years of experience using ML, text mining, and deep learning algorithms to solve challenging problems. Received “Exceeds Expectations Award” for developing Automated analytical tool that resolved issues 40% faster and reduced the incident tickets by 33%. Strong accomplishment of building unique data science applications, now aspiring to bring actionable solutions to real-time industry problems.
Interests
- Data Science
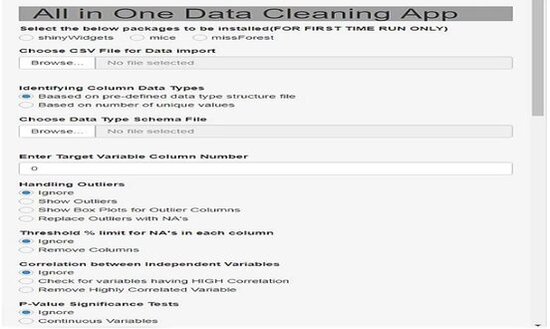
- Building Data Science Applications
- Automating Applications
- Text Mining
- Deep Learning
Education
MS in Business Analytics - Specilization in Data Science, 2020
University of Illinois at Chicago
Bachelors in Electronics and Communication Engineering, 2016
Chaitanya Engineering College